Programming
Assignment 2: |
|
|
|
|
Assigned: Monday, September 17, 2012
Due: 12:00 noon, Monday, October 1, 2012
Files
Overview
Preparation Create a programs/2 directory within your comp411 directory. All of your files for this assignment should be stored in the programs/2 subdirectory.
Teamwork You are strongly encouraged to do this assignment and all other programming assignments using pair programming. When you submit your assignment, indicate the composition of your team (names, student ids, and email addresses) in your README file.
If you cannot find a partner and would like one, send an email to comp411@rice.edu and we will try to find one for you. Teams of more than two members are not permitted.
Task Your task is to write three interpreters for Jam: one that performs call-by-value (big-step) evaluation, one that performs call-by-name evaluation, and one that performs call-by-need evaluation. The input to your interpreter will be a Jam program in the concrete syntax defined in Assignment 1. We are providing a parsers written in Java that accepts this syntax, but you are encouraged to use your solution to Assignment 1 as the parser for this assignment. If you use your own parser, make sure that the map construct accepts an empty parameter list. The Jam grammar is easier to read if the the last line of the definition of <exp> is revised to read
map { <prop-id-list> } to <exp>
where the curly braces { } state that the <prop-id-list> is optional. You may use the same lexer with your parser that you used in Assignment 1.
Call-by-value and call-by-name We will defer the discussion of call-by-need evaluation until the next section. If you do not understand the semantics of the Jam let construct, please read the Input Language Specification section below before the remainder of this section.
Call-by-need evaluation is a simple "optimization" of call-by-name evaluation, so we must explain call-by-name evaluation first. The difference between call-by-value evaluation and call-by-name evaluation is straightforward. Consider a substitution-based (syntactic) semantics for Jam analogous to the one we gave in Lecture 4 for the language LC. In call-by-value evaluation, the arguments in a procedure application (class App in the Java representation of Jam abstract syntax) are reduced to values before the arguments are substituted into the procedure body. In call-by-name evaluation, the argument expressions are substituted into the procedure body without being evaluated! These argument expressions are evaluated if and when their values are demanded during the evaluation of the body. This difference is codified by the differences in the reduction rules for procedure applications.
In call-by-value,
(mapto
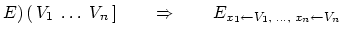
where ![]() are values. Hence the procedure body in an application is not evaluated
until the arguments are reduced to values.
are values. Hence the procedure body in an application is not evaluated
until the arguments are reduced to values.
In call-by-name,
(mapto
![$E) [ M_1 \; \dots \; M_n ] \qquad \Rightarrow \qquad E_{x_1 \leftarrow M_1, \; ..., \; x_n \leftarrow M_n}$](images/img5.png)
where ![]() are expressions. This rule performs the substitution immediately rather
than reducing
are expressions. This rule performs the substitution immediately rather
than reducing ![]() to values first.
to values first.
Since call-by-name defers the evaulation of arguments in procedure applications, some of those arguments may never be evaluated in some cases. As a result, there are Jam programs that converge to an answer for call-by-name but diverge for call-by-value (because some argument in a procedure application diverges that is never demanded in call-by-name evaluation).
For the sake of efficiency, your interpreter should maintain an environment of variable bindings instead of performing explicit substitutions. In the environment, each variable must be bound to a representation that can be evaluated on demand. Warning: beware of scoping problems in your call-by-name interpreter. Make sure that you evaluate each argument expression in the proper environment. Hint: it may be helpful to think of each argument expression as a procedure of no arguments.
We recommend that you use the generic PureList class in PureList.scala to represent an environment.
Call-by-need The call-by-name approach to evaluation is wasteful because it re-evaluates an argument expression every time the corresponding parameter is evaluated. By using the list representation for environments and performing destructive operations on data, it is possible to eliminate this wasteful practice and only evaluate each argument expression once, the first time its value is demanded. This evaluation protocol is called call-by-need. For functional languages like Jam, there is no difference in the observable behavior or call-by-name and call-by-need, except that the latter is generally more efficient.
Testing You are expected to write unit tests for all of your non-trivial methods or functions. For more information, refer back to Assignment 1. Since there is no straightforward way to inspect closures or environments (without presuming a particular implementation), the direct output of environments or closures will not be tested. We can still however test aspects of a closure. For example: arity(map x to x).
The visible part (for testing) of your program must include the toplevel class: Interpreter containing the methods callByValue(), callByName(), and callByNeed(). The interface JamVal is defined in the provided parser library files.
The Interpreter class must support two constructors: Interpreter(String filename) which takes input from the specified file and Interpreter(Reader inputStream) which takes input from the specified Reader. Store your source program in a file named Interpreter.scala. In summary, your should create a source file Interpreter.scala matching the following template:
/** file Interpreter.scala **/
class EvalException(msg: String) extends RuntimeException(msg)
class Interpreter(reader: java.io.Reader) {
def this(fileName: String) = this(new java.io.FileReader(fileName))
val ast: AST = new Parser(reader).parse()
def callByValue: JamVal = throw new UnsupportedOperationException("Unimplemented")
def callByName: JamVal = throw new UnsupportedOperationException("Unimplemented")
def callByNeed: JamVal = throw new UnsupportedOperationException("Unimplemented")
}
Choice of Language Generic Java (Java 5/6/7) and Scala are the only languages permitted for this assignment.
Input Language Specification
The following paragraphs define the Jam subset that your interpreter should handle and the new parser's input language.
Your interpreter should accept the Jam language including:
- the unary operators +, -,
~, and - the binary operators >, >=, !=,
+, -,
/, *, =, <,<=,&, |, and - the primitive Jam operations, namely cons?, empty? number?, function?, arity, list?, cons, first, and rest
The supported operators have exactly the same meaning
as their Scheme counterparts
(where the unary operator ~ is identified
with the Scheme not function, and
the binary operators & and |
are identified with the Scheme and and
or operators) with two exceptions:
/means the integer division,- = and != mean equality and inequality on arbitrary objects.
The binary operator =
behaves exactly like the Scheme equal? function, i.e. structural
equality for objects and identity for closures (functions). For closures,
the only way that functions can be equal is if they are actually the same
object, i.e. they were created by the same allocation.
Some instructive examples of Jam semantics include:
- 5 = 5 evaluates to true
- 5 = 6 evaluates to false
- cons(1,cons(2,empty))=cons(1,cons(2,empty)) evaluates to true
- cons(1,cons(2,empty))=cons(1,cons(3,empty)) evaluates to false
- cons(1,cons(2,empty))=cons(1,empty) evaluates to false
- cons? = cons? evaluates to true
- cons? = empty? evaluates to false
- cons? = (map x to x) evaluates to false
- (map x to x) = (map x to x) evaluates to false, because the two maps are distinct objects in memory.
- let m:=(map x to x); in m = m evaluates to true in call-by-value because the right-hand side of the definition is evaluated once, and from that point on m refers to the same object; to false in call-by-name, because the right-hand side is evaluated each time m is used, so the two objects being compared are not created during the same allocation; and to true in call-by-need, because the right-hand side of the definition is evaluated the first time m is used and from then on refers to that object.
- The equality operation defined on closures in the two bullets above has implications on the equality of lists: you have to compare two lists item by item using Jam =.
By Scheme, we mean the intermediate language with lambda defined in DrRacket used in Comp 210 and Comp 211.
The preceding definition of equality for closures is what is commonly done in languages like Scheme, Java, and C#, but it is unappealing from a mathematical perspective. Many common algebraic transformations break if closures are involved. There are more elegant ways to define equality on closures but they are more expensive. If we "flatten" closure representations so that a closure consists of a lambda-expression (AST map) M and a list of the bindings of the free variables in M, then we can compare the lambda-expressions (as ASTs) and the bindings of the free variables (recursively invoking equality testing of objects). For this assignment, we are using the common, inelegant definition which is easy to implement.
The meanings of the primitive functions are as follows:
- cons?
- p -> whether p was created by cons().
cons?(empty) = false - empty?
- p -> whether p is empty.
- number?
- p -> whether p is a number
- function?
- p -> whether p is a function (ie a map or a primitive function)
- arity
- p -> how many parameters does the function/primitive p take.
Evaluation error if a non-function is passed in. - list?
- p -> whether p is a list (anything constructed by cons(), or empty)
- cons
- p, q -> a cons (a list entry).
p can be anything.
q must be a list (something created by cons() or empty); Evaluation error otherwise. - first
- p -> The first element of list p
Evaluation error if p was not created by cons() (ie p is not a list or p is empty) - rest
- p -> The list p with the first element removed
Evaluation error if p was not created by cons() (ie p is not a list or p is empty)
The language constructs if, map, let, and application in JAM have the same meaning as if,lambda,let, and application in Scheme with two exceptions. First, the call-by-name version of Jam uses call-by-name semantics for procedure application. Second, when Jam if is given a non-boolean input in the test position, it aborts.
Your interpreter should abort by throwing an EvalException.
The Jam let construct is simply an abbreviation for the corresponding lambda application. Hence
let:=
;
:=
;
in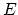
has exactly the same meaning as
(mapto
)
Hence, a let is a combination of a map and an application. Note that the semantics of let depend on whether the interpreter is using call-by-value or call-by-name.
Lists are created using cons and empty, where empty is the empty list. The one-element list (1) is created using cons(1,empty). Since the constructs returned by cons(...) and empty are lists, list? returns true for both of them. The following program evaluates to (true true):
cons(list?(cons(5,empty)),cons(list?(empty),empty))
and and or short-circuit even in call-by-value. That means they look just at their first operand and try to determine the result; only if they cannot determine it from just the first operand do they look at the second at the second operand. For example, true | x evaluates to true regardless of what value x has.
if works in a similar way: It evaluates the test expression. If it is true, it evaluates the consequence expression; if it is false, it evaluates the alternative expression. if never evaluates both the consequence and alternative expressions.
Representation of Program Values
A Jam program manipulates data values that are either numbers, booleans, lists, or procedure representations (closures). To standardize the visible behavior of Jam interpreters, we stipulate that your interpreters must observe the following conventions concerning the representation of Jam values in Java. Jam values must be represented using the JamVal interface and subclasses as defined in each of the three parser library files.
Testing and Submitting Your Program
The files tests/in1 and tests/in2 contain sample input programs for call-by-value. tests/name.in1 and tests/name.in2 contain samples for call-by-name and call-by-need. The files tests/out1 and tests/out2 contain the corresponding answer computed by the program as formatted by the toString method defined in support code.
Make sure that your program produces the same output on this sample input before submitting it. Create a README file in the your directory program/2 that
- contains nothing but the user names of the team members in lines 1 and 2 and a blank line as line 3,
- outlines the organization of your program, and
- specifies what testing process you used to confirm the correctness of your program.
Make sure that your README file is structured correctly:
- It has to be named README (all upper case, no .txt or anything)
- It has to be in the assignment's "root directory", e.g. ~/comp411/programs/2
- The
first two lines should only contain your usernames and nothing else.
The third line should be blank (if you're working alone, leave lines 2
and 3 blank), e.g.:
mgricken
dmp
This is where the readme text starts.
Your test data files should be stored in the programs/2 directory.
Each procedure or method in your program should include a short comment stating precisely what it does. For routines that parse a particular form of program phrase, give grammar rules describing that form.
To submit your program, make sure that everything that you want to submit is located in the directory comp411/programs/2 on CLE@R and type the command
/coursedata/courses/comp411/bin/turnin411 2
from within the comp411/programs directory.
The command will inform you whether or not your submission succeeded. Only submit one copy of your program per team. If you need to resubmit an improved version your program, submit it from the same account as the original so that the old version is replaced.
Implementation Hints
In your call-by-name interpreter, the argument expressions must be evaluated in the environment corresponding to their lexical context in the program. The free variables in argument expressions behave exactly like the free variables in functions (procedures).
The form of your interpreters should be very similar to the environment-based interpreters presented in class. You should represent ground values by their Object equivalents (where lists are represented using the PureList class in the parser library file) and functions either as explicit closure objects or as anonymous inner classes (the strategy pattern for representing functions). Implement each of the primitives using the corresponding Java primitive when possible. You will have to implement the function? and arity primitives on your own (which is straightforward).
Your interpreters should return the Java data values representing the answers to the specified Jam computations.
Note that unary and binary operators are not values while primitives
are. Unary and binary operators are not legal expressions; hence, they can never
be used as values. In addition, note that the binary operators &
and | are special: they do not evaluate their second arguments
unless it is necessary.
In writing your interpreters: follow the definition of the data. Your interpreters should contain a separate clause for each abstract syntax constructor. If you write the interpreters in Java, you should express it using the visitor pattern.
Remember to "factor out" repeated code patterns as you learned in Comp 210 and Comp 212.
Implement a very small subset of the primitives and operators first and get everything debugged. Then add support for the remaining ones.