Recurrent Neural Networks¶
In this lab we will experiment with recurrent neural networks. We will build a text generation model that predicts a word given the previous words, and hence will allow us to generate a sentence. This can easily be extended to generating a sentence description for a given input image. RNNs are a useful type of model for predicting sequences or handling sequences of things as inputs. In this lab we will use again Pytorch's nn library.
We will also be using the COCO dataset which includes images + textual descriptions (captions) + other annotations. We can browse the dataset here: http://cocodataset.org/#home
First, let's import libraries and make sure we have everything properly installed.
import torch, json, string
import torch.nn as nn
import torch.autograd
from torch.autograd import Variable
import torch.utils.data as data
import numpy as np
from nltk.tokenize import word_tokenize
1. Loading and Preprocessing the Text¶
Pytorch comes with a Dataset class for the COCO dataset but I will write my own class here. This class does two important things: 1) Building a vocabulary with the most frequent words, 2) Building utilities to convert a sentence into a list of word ids, and back. We are not going to be using the images for the purposes of the lab but you will use them in the assignment questions.
from tqdm import tqdm_notebook as tqdm
class CocoCaptions(data.Dataset):
# Load annotations in the initialization of the object.
def __init__(self, captionsFile, vocabulary = None):
self.data = json.load(open(captionsFile))
self.imageIds = self.data['images']
self.annotations = self.data['annotations']
# Build a vocabulary if not provided.
if not vocabulary:
self.build_vocabulary()
else:
self.vocabulary = vocabulary
# Build a vocabulary using the top 5000 words.
def build_vocabulary(self, vocabularySize = 5000):
# Count words, this will take a while.
word_counter = dict()
for annotation in tqdm(self.annotations, desc = 'Building vocabulary'):
words = word_tokenize(annotation['caption'].lower())
for word in words:
word_counter[word] = word_counter.get(word, 0) + 1
# Sort the words and find keep only the most frequent words.
sorted_words = sorted(list(word_counter.items()),
key = lambda x: -x[1])
most_frequent_words = [w for (w, c) in sorted_words[:vocabularySize]]
word2id = {w: (index + 1) for (index, w) in enumerate(most_frequent_words)}
# Add a special characters for START, END sentence, and UNKnown words.
word2id['[END]'] = 0
word2id['[START]'] = len(word2id)
word2id['UNK'] = len(word2id)
id2word = {index: w for (w, index) in word2id.items()}
self.vocabulary = {'word2id': word2id, 'id2word': id2word}
# Transform a caption into a list of word ids.
def caption2ids(self, caption):
word2id = self.vocabulary['word2id']
caption_ids = [word2id.get(w, word2id['UNK']) for w in word_tokenize(caption.lower())]
caption_ids.insert(0, word2id['[START]'])
caption_ids.append(word2id['[END]'])
return torch.LongTensor(caption_ids)
# Transform a list of word ids into a caption.
def ids2caption(self, caption_ids):
id2word = self.vocabulary['id2word']
return string.join([id2word[w] for w in caption_ids], " ")
# Return imgId, and a random caption for that image.
def __getitem__(self, index):
annotation = self.annotations[index]
return annotation['image_id'], self.caption2ids(annotation['caption'])
# Return the number of elements of the dataset.
def __len__(self):
return len(self.annotations)
# Let's test the data class.
trainData = CocoCaptions('annotations/captions_train2014.json')
print('Number of training examples: ', len(trainData))
# It would be a mistake to build a vocabulary using the validation set so we reuse.
valData = CocoCaptions('annotations/captions_val2014.json', vocabulary = trainData.vocabulary)
print('Number of validation examples: ', len(valData))
# Print a sample from the training data.
imgId, caption = trainData[0]
print('imgId', imgId)
print('caption', caption.tolist())
print('captionString', trainData.ids2caption(caption))
2. Making a Data Loader that can Handle Sequences.¶
Handling sequences is special when processing batches of inputs because each sequence can have a different length. This makes batching complicated, and different libraries have different ways of handling this which might be easier or harder to deal with. Here we are padding the sequences to the maximum sequence length in a given batch. Additionally pytorch has nice utility functions that require sorting the sequences in a batch from longest to shortest.
# The batch builder will pack all sequences of different length into a single tensor by
# padding shorter sequences with a padding token.
def customBatchBuilder(samples):
imgIds, captionSeqs = zip(*samples)
# Sort sequences based on length.
seqLengths = [len(seq) for seq in captionSeqs]
maxSeqLength = max(seqLengths)
sorted_list = sorted(zip(list(imgIds), captionSeqs, seqLengths), key = lambda x: -x[2])
imgIds, captionSeqs, seqLengths = zip(*sorted_list)
# Create tensor with padded sequences.
paddedSeqs = torch.LongTensor(len(imgIds), maxSeqLength)
paddedSeqs.fill_(0)
for (i, seq) in enumerate(captionSeqs):
paddedSeqs[i, :len(seq)] = seq
return imgIds, paddedSeqs.t(), seqLengths
# Data loaders in pytorch can use a custom batch builder, which we are using here.
trainLoader = data.DataLoader(trainData, batch_size = 128,
shuffle = True, num_workers = 0,
collate_fn = customBatchBuilder)
valLoader = data.DataLoader(valData, batch_size = 128,
shuffle = False, num_workers = 0,
collate_fn = customBatchBuilder)
# Now let's try using the data loader.
index, (imgIds, paddedSeqs, seqLengths) = next(enumerate(trainLoader))
print('imgIds', imgIds)
print('paddedSequences', paddedSeqs.size())
print('seqLengths', seqLengths)
3. Building our model using a Recurrent Neural Network.¶
We will build a model that predicts the next word based on the previous word using a recurrent neural network. Additionally we will be using an Embedding layer which will assign a unique vector to each word. The network will be trained with a softmax + negative log likelihood loss. Similar to classification we will be trying to optimize for the correct word at each time-step.
# By now, we should know that pytorch has a functional implementation (as opposed to class version)
# of many common layers, which is especially useful for layers that do not have any parameters.
# e.g. relu, sigmoid, softmax, etc.
import torch.nn.functional as F
class TextGeneratorModel(nn.Module):
# The model has three layers:
# 1. An Embedding layer that turns a sequence of word ids into
# a sequence of vectors of fixed size: embeddingSize.
# 2. An RNN layer that turns the sequence of embedding vectors into
# a sequence of hiddenStates.
# 3. A classification layer that turns a sequence of hidden states into a
# sequence of softmax outputs.
def __init__(self, vocabularySize):
super(TextGeneratorModel, self).__init__()
# See documentation for nn.Embedding here:
# http://pytorch.org/docs/master/nn.html#torch.nn.Embedding
self.embedder = nn.Embedding(vocabularySize, 300)
self.rnn = nn.RNN(300, 512, batch_first = False)
self.classifier = nn.Linear(512, vocabularySize)
self.vocabularySize = vocabularySize
# The forward pass makes the sequences go through the three layers defined above.
def forward(self, paddedSeqs, initialHiddenState):
batchSequenceLength = paddedSeqs.size(0) # 0-dim is sequence-length-dim.
batchSize = paddedSeqs.size(1) # 1-dim is batch dimension.
# Transform word ids into an embedding vector.
embeddingVectors = self.embedder(paddedSeqs)
# Pass the sequence of word embeddings to the RNN.
rnnOutput, finalHiddenState = self.rnn(embeddingVectors, initialHiddenState)
# Collapse the batch and sequence-length dimensions in order to use nn.Linear.
flatSeqOutput = rnnOutput.view(-1, 512)
predictions = self.classifier(flatSeqOutput)
# Expand back the batch and sequence-length dimensions and return.
return predictions.view(batchSequenceLength, batchSize, self.vocabularySize), \
finalHiddenState
# Let's test the model on some input batch.
vocabularySize = len(trainData.vocabulary['word2id'])
model = TextGeneratorModel(vocabularySize)
# Create the initial hidden state for the RNN.
index, (imgIds, paddedSeqs, seqLengths) = next(enumerate(trainLoader))
initialHiddenState = Variable(torch.Tensor(1, paddedSeqs.size(1), 512).zero_())
predictions, _ = model(torch.autograd.Variable(paddedSeqs), initialHiddenState)
print('Here are input and output size tensor sizes:')
# Inputs are seqLength x batchSize x 1
print('inputs', paddedSeqs.size()) # 10 input sequences.
# Outputs are seqLength x batchSize x vocabularySize
print('outputs', predictions.size()) # 10 output softmax predictions over our vocabularySize outputs.
3. Sampling a New Sentence from the Model.¶
The code below uses the RNN network as an RNN cell where we only pass one single input word, and a hidden state vector. Then we keep passing the previously predicted word, and previously predicted hidden state to predict the next word. Since the given model is not trained, it will just output a random sequence of words for now. Ideally, the trained model should also learn when to [END] a sentence.
def sample_sentence(model, use_cuda = False):
counter = 0
limit = 200
words = list()
# Setup initial input state, and input word (we use "the").
previousWord = torch.LongTensor(1, 1).fill_(trainData.vocabulary['word2id']['the'])
previousHiddenState = torch.autograd.Variable(torch.Tensor(1, 1, 512).zero_())
if use_cuda: previousHiddenState = previousHiddenState.cuda()
while True:
# Predict the next word based on the previous hidden state and previous word.
inputWord = torch.autograd.Variable(previousWord)
if use_cuda: inputWord = inputWord.cuda()
predictions, hiddenState = model(inputWord, previousHiddenState)
nextWordId = np.random.multinomial(1, F.softmax(predictions.squeeze()).data.cpu().numpy(), 1).argmax()
words.append(trainData.vocabulary['id2word'][nextWordId])
# Setup the inputs for the next round.
previousWord.fill_(nextWordId)
previousHiddenState = hiddenState
# Keep adding words until the [END] token is generated.
if nextWordId == trainData.vocabulary['word2id']['[END]'] or counter > limit:
break
counter += 1
words.insert(0, 'the')
words.insert(0, '[START]')
return string.join(words, " ")
print(sample_sentence(model, use_cuda = False))
3. Training the Model¶
Now that data is pre-processed, we can try training the model. An important part is to define our target labels or ground-truth labels. In this text generation model, we want to predict the next word based on the previous word. So we need to provide as the target a shifted version of the input sequence. The code below looks a lot like the code used for training previous models with only small modifications.
import tqdm as tqdmx
from tqdm import tqdm_notebook as tqdm
tqdmx.tqdm.get_lock().locks = []
def train_rnn_model(model, criterion, optimizer, trainLoader, valLoader, n_epochs = 10, use_gpu = False):
return
Now to the actual training call, notice how unlike previous experiments we are using here RMSprop which is a different type of optimizer that is often preferred for recurrent neural networks, although others such as SGD, and ADAM will also work. Additionally we are using nn.NLLLoss for the loss function, which is equivalent to the nn.CrossEntropyLoss function used before. The only difference is that nn.CrossEntropyLoss does the log_softmax operation for us, however in our implementation, we already applied log_softmax to the outputs of the model.
vocabularySize = len(trainData.vocabulary['word2id'])
model = TextGeneratorModel(vocabularySize)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0005)
# Train the previously defined model.
train_rnn_model(model, criterion, optimizer, trainLoader, valLoader, n_epochs = 10, use_gpu = True)
Lab Questions (10pts)¶
1. (2pts) What is the number of parameters of the TextGeneratorModel?
# Show how did you come up with that number here.
2. (4pts) Provide an implementation for the function train_rnn_model from section 3, this will be similar to the train_model function used in the previous lab. Then train the model and report a few sentences generated by your model. Use the following figure as reference to make sure you are using the right inputs and targets to train the model. The loss function between predictions and targets should be nn.CrossEntropyLoss(), so you might need to collapse the batch and sequence-length dimensions before passing them to the loss function.
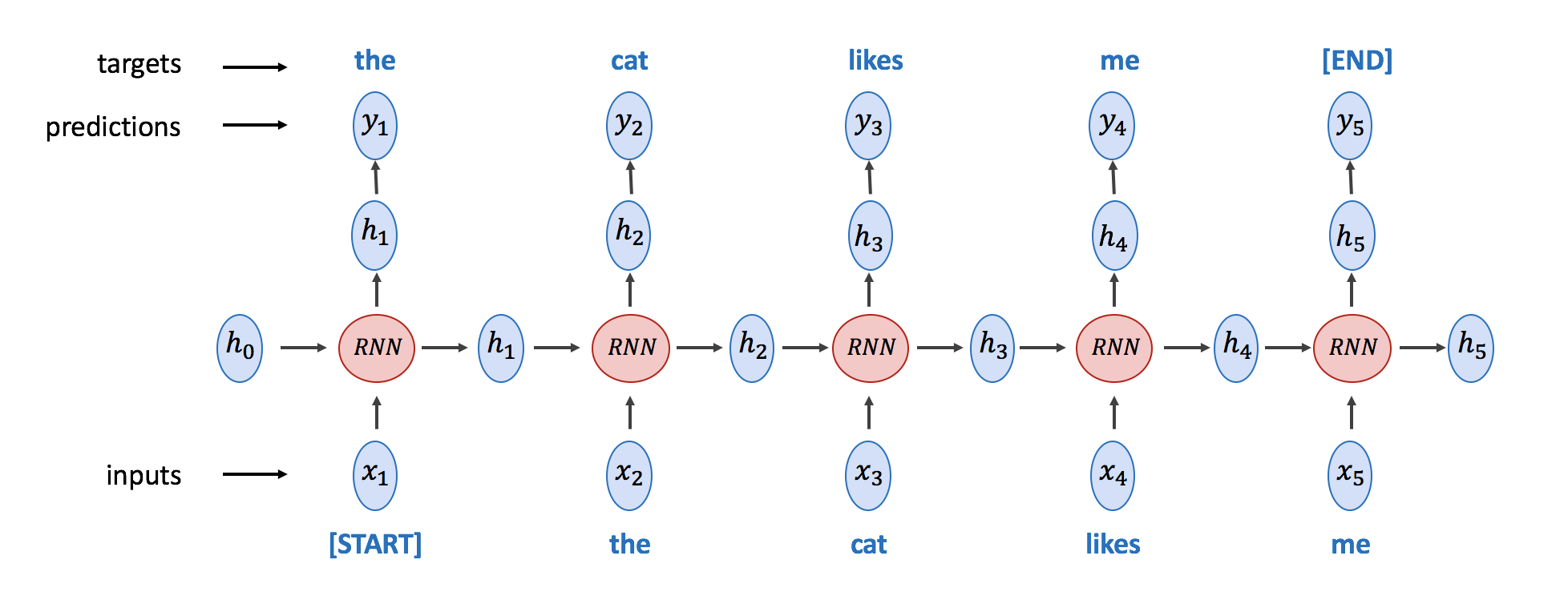
# implement train_rnn_model and then train the model using this function.
# Show here a couple of sentences sampled from your model.
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
3. (4pts) Create an ImageCaptioningModel class here that predicts a sentence given an input image. This should be an implementation of the model in this paper https://arxiv.org/pdf/1411.4555.pdf (See figure 3 in the paper). This model is very similar to the one implemented in this lab except that the first RNN cell gets the output of a CNN as its input. I'm also illustrating it below using a figure similar to the one in the previous question. For the CNN use Resnet-18. Note: You do not need to train this model, only define it. Feel free to start from the code for the TextGeneratorModel. 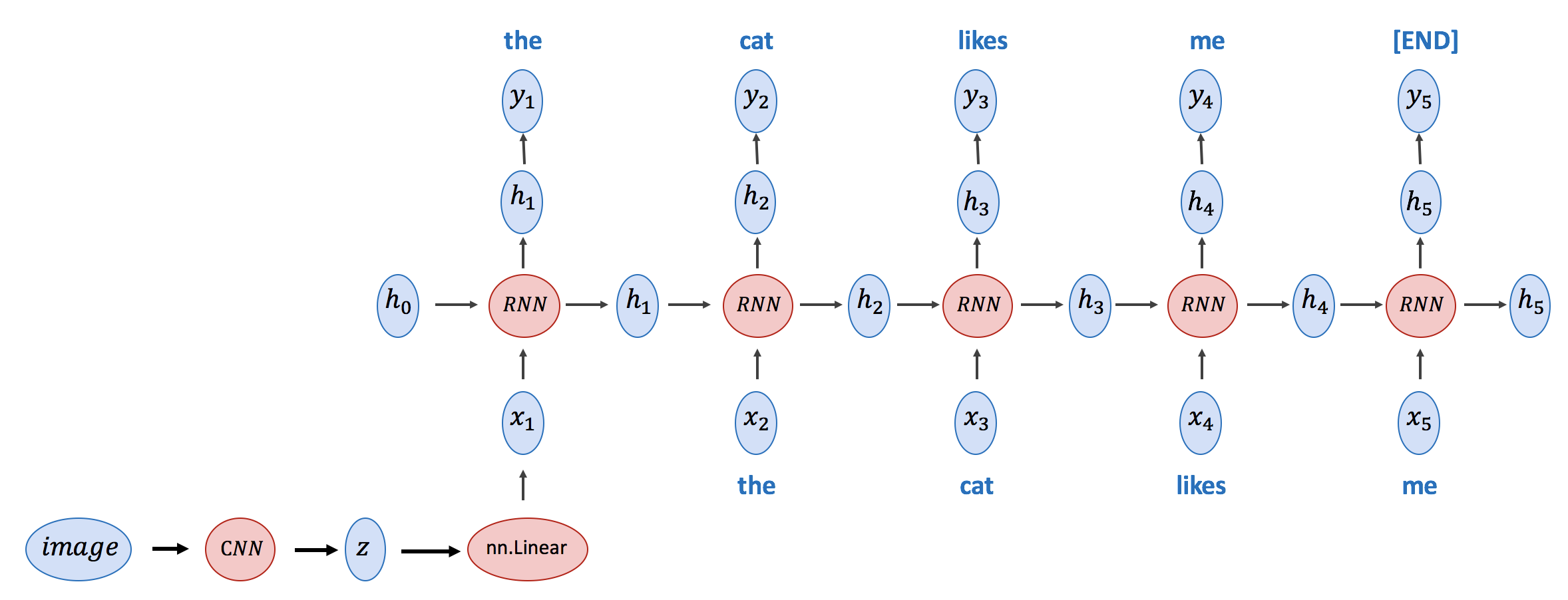
Optional Questions (8pts)¶
1. (1pts) What is the number of parameters of the ImageCaptioningModel from Q3?
# Show how did you come up with that number here.
2. (3pts) Modify the TextGeneratorModel to use an LSTM instead, and retrain the model. Report results using this model.
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
print(sample_sentence(model, use_cuda = True))
3. (4pts) In this question, you will have to reconstruct an input image from its activations. I will not provide you with the image, only the activation values obtained for a certain layer. You will have access to the code that was used to compute these activations. You will have to use back-propagation to reconstruct the input image. Show the reconstructed input image and tell us who is in the picture. Note: Look at the content reconstruction from outputs performed in https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Gatys_Image_Style_Transfer_CVPR_2016_paper.html
import torchvision.models as models
model = models.vgg16(pretrained = True)
import pickle
import torchvision.transforms as transforms
from PIL import Image
preprocessFn = transforms.Compose([transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean = [0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
def model_F(input, kOutput = 19):
prev_input = input
for layer_id in range(0, kOutput + 1):
current_input = model.features[layer_id](prev_input)
prev_input = current_input
return current_input
# Read the incognito image. (Obviously this is not provided in the Lab assignment.)
image = preprocessFn(Image.open('incognito.jpg').convert('RGB'))
image = Variable(image.unsqueeze(0))
# Obtain the output of the VGG layer 19.
model.eval()
target = Variable(model_F(image).data) # Repack variable.
print('image.size()', image.size())
print('layer-19-output.size()', target.size())
torch.save(target.data, open('layer-19-output.p', 'w'))
import matplotlib.pyplot as plt
%matplotlib inline
def imshow(img):
# convert torch tensor to PIL image and then show image inline.
img = transforms.ToPILImage()(img[0].cpu() * 0.5 + 0.5) # denormalize tensor before convert
plt.imshow(img, aspect = None)
plt.axis('off')
plt.gcf().set_size_inches(4, 4)
plt.show()
target = torch.load(open('layer-19-output.p'))
print(target.size())
# Your solution goes here. Show the reconstructed input and tell us who is depicted in the incognito.jpg image.